Table of Contents [expand]
Last updated December 28, 2022
This architecture shows how to coordinate a set of decoupled, fungible, and independent services on Heroku by using Apache Kafka on Heroku as a scalable, highly available, and fault-tolerant asynchronous communication backbone.
Scenario
- You have a large number of microservices that must communicate asynchronously.
- You want your microservices to be decoupled, fungible, and independently maintained.
- You have one or more services that produce events that must be processed by many services.
- You want to use a microservices communication pattern that is more decoupled than the typical HTTPS approach.
Architecture
This reference architecture uses Apache Kafka on Heroku to coordinate asynchronous communication between microservices. Here, services publish events to Kafka while downstream services react to those events instead of being called directly. In this fashion, event-producing services are decoupled from event-consuming services. The result is an architecture with services that are scalable, independent of each other, and fungible.
Using Kafka for asynchronous communication between microservices can help you avoid bottlenecks that monolithic architectures with relational databases would likely run into. Because Kafka is highly available, outages are less of a concern and failures are handled gracefully with minimal service interruption. As Kafka retains data for a configured amount of time you have the option to rewind and replay events as required.
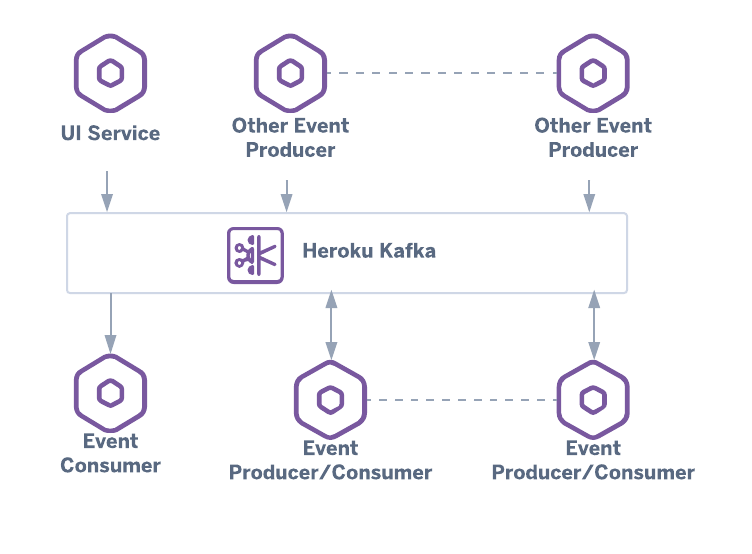 Apache Kafka for scalable, decoupled coordination of a set of microservices
Apache Kafka for scalable, decoupled coordination of a set of microservices
Components
Required
- An Apache Kafka on Heroku instance, which acts as the broker
- A set of individual services that are configured to consume messages from Kafka
- A (potentially overlapping) set of services that are configured to publish events to Kafka
Implementation Guidelines
Setting Up the Microservices
- Isolate Kafka consumers and producers into their own Heroku apps and scale them as needed.
- If you’re transforming a monolith into microservices, see this blog post, which documents one approach to moving to such a system.
- Read the documentation on various client libraries to your apps to communicate with Kafka.
Asynchronous Messaging & Kafka Setup
- Provision the Apache Kafka on Heroku add-on.
- Be sure to share the same Kafka instance across all of the apps that represent your producers and consumers.
- Don’t be afraid to take a hybrid approach to microservices communication; sometimes it makes sense to use both HTTPS and Kafka messages.
- For more information on configuring Kafka, see the Apache Kafka on Heroku category.
Example Implementation
The following architecture diagram depicts a simple event-driven microservice architecture, which you can deploy using this Terraform script.
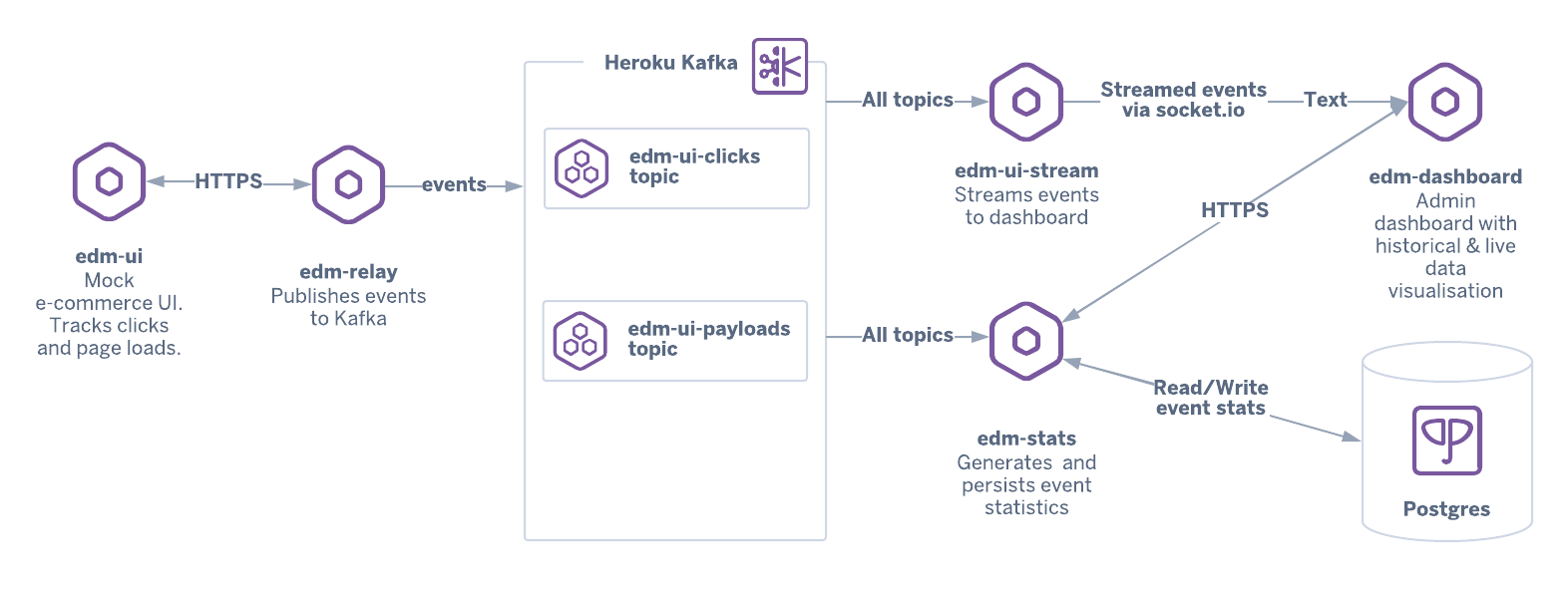
This particular example is a hybrid system that uses both asynchronous messaging and HTTPS. Events originate from a mock e-commerce application (edm-ui) and are sent over HTTPS to edm-relay, which then writes them to their respective Kafka topics. Those messages are consumed by two different apps: edm-stream and edm-stats.
The edm-stats and edm-stream apps are part of different Kafka consumer groups so that all events are processed by each service. Each service has a different business purpose driven by events:
edm-streamstreams events directly toedm-dashboardvia Socket.io.edm-statsrecords statistical information about events, saves that data in a Heroku Postgres database, and provides a simple API for that data.
Finally, edm-dashboard is a data visualization UI that initially requests historical statistical data from edm-stats over HTTPS and receives streaming events from edm-stream via Socket.io.
Because of the decoupled nature of this architecture, adding additional services to consume events is easy: create another service that is part of a new consumer group, and it’s now subscribed to the topics of your choice.
See Using Terraform with Heroku for details on how to use Terraform with Heroku, and this Terraform script, which deploys this entire architecture.
Pros / Cons
Pros
- Services are decoupled, fungible, and independent.
- Messages are buffered and consumed when resources are available.
- Services scale easily for high-volume event processing.
- Kafka is highly available and fault-tolerant.
- Consumers / producers can be implemented in many different languages.
Cons
- This architecture introduces some operational complexity and requires Kafka knowledge.
- Handling partial failures can be challenging.
Additional Reading
Blog Posts
- Deconstructing Monolithic Applications into Services
- Managing Real-time Event Streams and SQL Analytics with Apache Kafka on Heroku, Amazon Redshift, and Metabase